赫夫曼编码(压缩与解压 Java代码实现)
本文共 5341 字,大约阅读时间需要 17 分钟。
代码存在细微bug正在修改中。。。
简单编码
有一个字符串:"hello world " 是先把字符串转换为ASCLL码,再把10进制的ASCLL码转换成2进制的数进行编码。
赫夫曼编码
有一个字符串:“hello world” 统计每一个字母出现的次数
h : 1 e : 1 l : 3 o : 2 w : 1r : 1d : 1 :1
根据次数构建出一棵赫夫曼树:
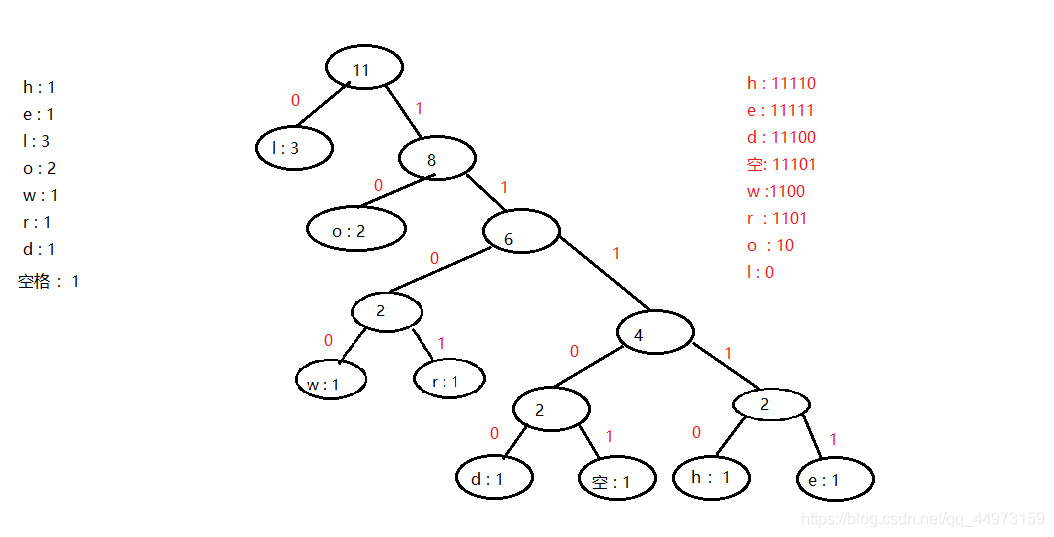 根据赫夫曼树,给各个字符,规定编码,向左的路径为0向右的路径为1,编码如上图:使用得到的编码把字符串进行编码:得到
根据赫夫曼树,给各个字符,规定编码,向左的路径为0向右的路径为1,编码如上图:使用得到的编码把字符串进行编码:得到 11110111110010111011100110110011100 赫夫曼编码(把字符串转化为编码)
思路分析
- Node { data (存放数据),weight (权值),left 和right }
- 得到"hello world"对应的byte[]数组
- 编写-一个方法,将准备构建赫夫曼树的Node节点放到List ,形式[Node[date=100, weight =1], Node[date=32,weight =1]… ] 体现
h : 1 e : 1 l : 3 o : 2 w : 1 r : 1 d : 1 :1 - 可以通过 list 创建对应的赫夫曼树
代码实现
构建节点类class HCNode implements Comparable{ Byte data; int weight; // 节点的值、权值 HCNode left; // 左右子节点的指针 HCNode right; public HCNode(Byte data, int weight) { this.data = data; this.weight = weight; } // 前序遍历 public void DLR() { System.out.println(this);// 先输出根节点 // 左子树递归 if (this.left != null) { this.left.DLR(); } // 右子树递归 if (this.right != null) { this.right.DLR(); } } @Override public String toString() { return "HCNode[ data =" + data + ", weight = " + weight + "]"; } @Override public int compareTo(HCNode o) { return this.weight - o.weight; // 从小到大排序 }}
将字符串转换为Ascll码并且进行编码
import java.util.*;public class HuffmanTreeCode { public static List getNodes(byte[] bytes) { // 创建 ArrayList nodes = new ArrayList (); // 遍历bytes统计每个字母出现的次数 map[k->v] Map counts = new HashMap<>(); for (byte b : bytes) { Integer count = counts.get(b); if (count == null) { // 还不存在这个key counts.put(b, 1); } else { counts.put(b, count + 1); } } // 把键值对转成HCNode对象 for (Map.Entry entry : counts.entrySet()) { nodes.add(new HCNode(entry.getKey(), entry.getValue())); } return nodes; } public static HCNode create(List nodes) { while (nodes.size() > 1) { // 先进行排序 Collections.sort(nodes); // 取出最小的俩个数据 HCNode leftnode = nodes.get(0); HCNode rightnode = nodes.get(1); // 构建新的二叉树 HCNode parent = new HCNode(null, leftnode.weight + rightnode.weight); parent.left = leftnode; parent.right = rightnode; // 从当中删除使用过的子节点 nodes.remove(leftnode); nodes.remove(rightnode); // 把父节点加入进去 nodes.add(parent); } // System.out.println("第一次处理后:" +nodes); return nodes.get(0); } // 通过赫夫曼树生成0和1的编码 public static byte[] zip(byte[] bytes, Map huffmancode) { // 赫夫曼编码表转成编码后的编码 StringBuilder StringBuilder = new StringBuilder(); // 遍历bytes for (byte b : bytes) { StringBuilder.append(huffmancode.get(b)); } System.out.println("StringBuilder =" + StringBuilder); // 把 01100110101101110010110111110000 转成byte[] int len; if (StringBuilder.length() % 8 == 0) { len = StringBuilder.length() / 8; } else { len = StringBuilder.length() / 8 + 1; } // 创建存储压缩后的huffmancodebyte byte[] huffmancodebyte = new byte[len]; int index = 0;// 记录下来是第几个byte for (int i = 0; i < StringBuilder.length(); i += 8) { // 每8位对应一个byte,步长为8 String strByte; if (i + 8 > StringBuilder.length()) { // 最后一个不够8位 strByte = StringBuilder.substring(i); } else { strByte = StringBuilder.substring(i, i += 8); } // strByte转换成byte huffmancodebyte[index] = (byte) Integer.parseInt(strByte, 2); index++; } return huffmancodebyte; } // 赫夫曼树对应的编码表,放在map当中。 // 拼接路径,定义一个StringBuilder存储叶子节点的路径 static Map huffmancode = new HashMap (); static StringBuilder StringBuilder = new StringBuilder(); // node 当前节点 code 路径 左0右1 StringBuilder用于路径拼接 public static void Getcode(HCNode node, String code, StringBuilder StringBuilder) { StringBuilder StringBuilder2 = new StringBuilder(StringBuilder); // 把code加入到StringBuilder2 StringBuilder2.append(code); if (node != null) { // 判断节点是不是叶子节点 if (node.data == null) { // 非叶子节点 // 向左递归处理 Getcode(node.left, "0", StringBuilder2); // 向右递归处理 Getcode(node.right, "1", StringBuilder2); } else { huffmancode.put(node.data, StringBuilder2.toString()); } } } public static Map Getcode(HCNode root) { if (root == null) { return null; } Getcode(root.left, "0", StringBuilder); Getcode(root.right, "1", StringBuilder); return huffmancode; } // 前序遍历 public static void DLR(HCNode root) { if (root != null) { root.DLR(); } else { System.out.println("二叉树为空,无法遍历"); } } private static byte[] huffmanZip(byte[] bytes) { List nodes = getNodes(bytes); // 创建赫夫曼树 HCNode root = create(nodes); // root.DLR(); // 生成赫夫曼编码 Map huffmancode = Getcode(root); byte[] huffmancodebyte = zip(bytes, huffmancode); return huffmancodebyte; } public static void main(String[] args) { String str = "hello world"; // String str="i like like like java do you like a java"; byte[] strBytes = str.getBytes(); System.out.println("StrBytes = " + Arrays.toString(strBytes)); byte[] Hcode = huffmanZip(strBytes); System.out.println("Hcode =" + Arrays.toString(Hcode) + " , 长度" + Hcode.length); }} 经过赫夫曼编码之后可以在控制台看到输出结果,原本的StrBytes变成Hcode。
StrBytes = [104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]StringBuilder =01100110101101110010110111110000Hcode =[102, 45, 0, 0] , 长度4
赫夫曼解码(把编码转化为字符串)
定义俩个方法,其一:把byte编码转换成哈夫曼编码的二进制字符串
public static String ByteToBitString(boolean flag, byte b) { int temp = b; if (flag) { // 用于判断是否需要补位 // 如果是正数还需要进行补位 temp |= 256; // 按位与 256 = 1 0000 0000 | 0000 0001 = 1 0000 0001 } String str = Integer.toBinaryString(temp); // 返回的是temp补码 // System.out.println("str = " + str); if (flag) { return str.substring(str.length() - 8); } else { return str; } } 转载地址:http://ngmzi.baihongyu.com/
你可能感兴趣的文章
使用ORM工具进行数据访问
查看>>
使用ORM工具进行数据访问
查看>>
编译与部署Eclipse+Tomcat+MySQL+Liferay4.1.2
查看>>
POJ3728,The merchant(倍增LCA+分治)
查看>>
2019 ICPC Malaysia National,E. Optimal Slots(01背包变形)
查看>>
洛谷P1638 逛画展(双向队列)
查看>>
POJ2892,Tunnel Warfare(线段树维护连续区间)
查看>>
POJ3468,A Simple Problem with Integers(线段树-区间查询-区间更新)
查看>>
杭电ACM——6463(思维)
查看>>
杭电ACM——1061,Rightmost Digit(思维)
查看>>
杭电ACM——1087,Super Jumping! Jumping! Jumping!(DP)
查看>>
杭电ACM——fatmouse's speed(DP)
查看>>
杭电ACM——毛毛虫(DP)
查看>>
杭电ACM——humble numbers(DP)
查看>>
杭电ACM——6467,简单数学题(思维)
查看>>
杭电ACM——天上掉馅饼(DP)
查看>>
杭电ACM——1086,You can Solve a Geometry Problem too(思维)
查看>>
杭电ACM——2057,A + B Again(思维)
查看>>
codeforces——1097B,Petr and a Combination Lock(搜索)
查看>>
杭电ACM——2069,Coin Change(DP)
查看>>